Computer Science - C++ Lesson 43: Hash-Coded Data Storage
OBJECTIVES:
The student will use hash-coded data storage to store and search for data in a hash-table.
The student will state the order of a hash-coded search algorithm.
INTRODUCTION:
The data file (Id/Inv information) used in this curriculum guide has been stored in a variety of ways. Of the data structures studied (arrays, linked lists, binary trees), the fastest search algorithm was O(log2N) for a binary tree or binary search of an ordered array. It is possible to improve on these algorithms, reducing the order of searching to O(1) or constant time. The method is called hash-coded data storage.
An example of hashing could occur on the first day of school. When distributing student schedules, one long line is usually broken up into smaller lines, often by grade level. This concept could be extended to 26 lines. Students line up according to the first letter of their last name. This is what hash-coded data storage is about - the breaking up and reorganization of one big list into lots of little lists.
The key topics for this lesson are:
A. Hashing Schemes
B. Dealing with Collisions
C. Order of a Hash-Coded Data Search
VOCABULARY:
| Hashing | HASH KEY |
| Hash table | COLLISIONS |
DISCUSSION: A. Hashing Schemes
1. The example of distributing student schedules illustrates a natural means of hashing. The first letter of the last name is used to locate the correct line.
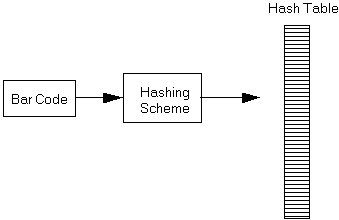
2. A hashing scheme involves converting a key piece of information into a specific location, thus reducing the amount of searching in the data structure. Instead of working with the entire list or tree of data, the hashing scheme tells you exactly where to store that data or search for it.
3. The bar coding system used by retail stores involves a sequence of 10 numerals. This system provides for 10 billion different possible products, 0-9,999,999,999. For quick access, an array of 10 billion locations would be nice but obviously impossible. Since it is unlikely a store would carry such a huge number of items, we need a system to store a list of products in a reasonably-sized array.
5. Suppose a store maintains a database of 10,000 bar codes out of the possible 10 billion different values. The values will be stored in an array called a hash table. Because an array has direct random access for every cell, using a hashing scheme will give us instantaneous access to a value being searched. The hash table is usually sized about 1.5 to 2.0 times as big as the maximum number of values stored. (The reason for this sizing will be apparent in a few sections.) Therefore we will create an array from 1..15000.
6. The hashing scheme will tell us where item XXXXX XXXXX is stored out of the 15,000 locations. A hashing algorithm is a sequence of steps, usually mathematical in nature, which converts a key field of information into a location in the hash table.
7. These “key-to-address transformations” are called hashing functions or hashing algorithms. When the key is composed of character data, the ordinal value of the characters is used so that mathematical processing can take place. Some common hash functions are:
a. Division. The key is subject to modulo division by an integer (often a prime) equal to or slightly smaller than the desired size of the array. The result of the division determines which short list to work with in the hash table.
b. Midsquare. The key is squared and the digits in the middle are retained for the address. This probably would not work well with bar codes because they are such large numbers.
c. Folding. The key is divided into several parts, each of which are combined and processed to give an address. For example:
If the bar code = 70662 11001
1) group into pairs: 70 66 21 10 01
2) multiply the first three numbers together:
70 x 66 x 21 = 97020
3) add this number to the last two numbers:
97020 + 10 + 01 = 97031
4) find the remainder of modulo division by 14987 (using method a):
97031 % 14987 = 7109
5) address 7109 is the location to store bar code
70662 11001
8. The information stored in the address is more than the key field (bar code number). We must store all the fields related to this item, such as price and name of the item.
9. It is important to develop a good hashing function which avoids collisions in the hash table. For example, folding the bar code 66702 00110 using the scheme developed above, would result in the same address - 7109. It is called a collision because two values need to be stored in the same address.
10. This is why the hash table is sized about 1.5-2.0 times the number of expected data. If the hash table in our example were sized at 10,000, the number of items in the database, the likelihood of collisions is increased. We are trying to balance the need for spreading out the potential collisions against memory limitations, hence the recommended sizing.
B. Dealing
with Collisions
1. There are two methods of creating multiple storage locations for the same address in the hash table. One solution involves a matrix, while the other uses dynamic linked lists.
2. To implement the hash table as a matrix, an estimate of the maximum number of collisions at any one address must be made. The second dimension is sized accordingly.
apmatrix <item> table (15000,5);
3. This method has some major drawbacks. The size of this data structure has suddenly increased by a factor of five. The above table will have 75,000 cells, many of which will be empty. Also, what happens if a location must deal with more than 5 collisions?
4. A dynamic solution is much better. The linked lists will only increase as values are stored in that location in the hash table. In this version, the hash table will be an array of pointers.
const int MAX = 15000;
struct listNode
{
// list all the data members to describe the item
listNode *next;
};
typedef listNode* listPtr;
apvector<listPtr> hashTable (MAX, NULL);
5. The order of the values in the linked lists in unimportant. If the hashing scheme is a good one, the number of collisions will be minimal.
C. Order of a Hash-Coded Data Search
1. After scanning an item at a cash register, the number of steps required to find the price is constant:
a. Hash the bar code value and get the hash table location.
b. Go to that location in the hash table, traverse the linked list until you find the item.
c. Return the price.
2. The number of steps in this algorithm is constant. The hashing scheme tells the program exactly where to look in the hash table, therefore this type of search is independent of the amount of data stored. We categorize this type of algorithm as constant time, or O(1).
3. If the linked lists get lengthy, this could add a few undesirable extra steps to the process. A good hashing scheme will minimize the length of the longest list.
4. An interesting alternative to linked lists is the use of ordered binary trees to deal with collisions. For example, the hash table could consist of 10,000 potential binary trees, each ordered by a key field.
5. Remember that determining the order of an algorithm is only a categorization, not an exact calculation of the number of steps. A hashing scheme will always take more than one step, but the fixed number of steps is independent of the size of the data set, hence we call it O(1).
SUMMARY/REVIEW:
Hashing is a great strategy for storing and searching information,
especially where speed is a priority. This
now concludes our coverage of different methods of data storage in the
curriculum guide. As you continue in computer science, you will no doubt learn
about other data structures and algorithms.
Keep reading and learning!
ASSIGNMENT:
Lab Exercise L.A.43.1, Hashing